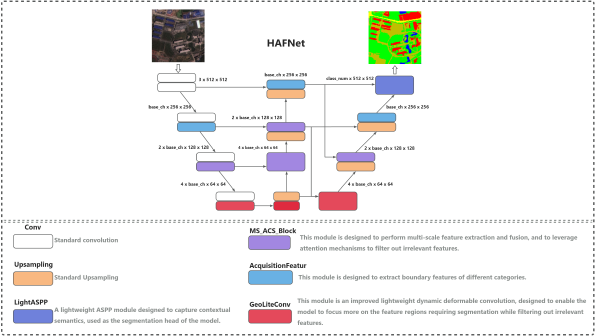
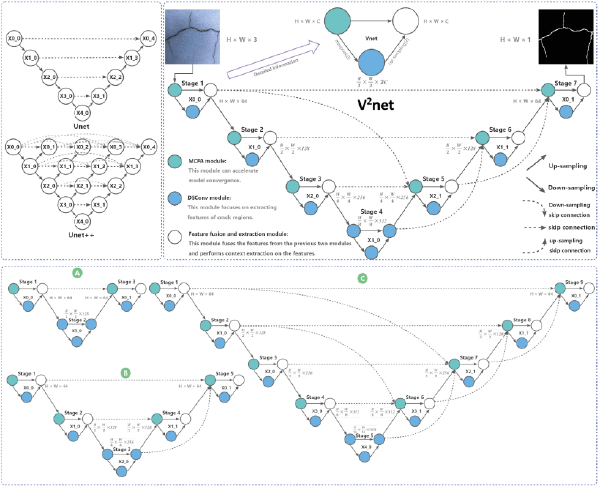
南巷/从模型结构到真实系统的项目沉淀。/星语 Vision:自研多模态大模型/星语 Vision:自研多模态大模型2026/05/01·1 分钟· 项目 CLIP VLM LoRA Image-Text星语 Vision 以图像-文本联合推理为目标,验证从视觉编码、token 融合到文本生成的多模态系统链路。基于 CLIP 视觉编码器提取图像表征。实现视觉 token 替换策略,将图像信息融入文本 Transformer 模型。完成端到端图像-文本推理验证,并支持预训练、SFT 与 LoRA 微调流程。在线体验:ModelScope。 订阅更新通过 RSS 获取新文章,也可以直接邮件联系我。RSS Email相关文章CodeLab-LLaMA2 / 星语 MoE:大模型训练实践2026/04/15·9 分钟项目 LLaMA2 Transformer MoE SFT LoRA RAGHAFNet:轻量化语义分割网络2026/02/10·1 分钟项目 Semantic Segmentation Lightweight Feature Fusion AttentionNxV2Net:裂缝分割科研代码2026/01/10·1 分钟项目 Crack Segmentation VNet MCFA SUES-CRACKClassification:通用图像分类训练模板2025/02/15·1 分钟项目 Classification ResNet EfficientNet SwanLab2018 Data Science Bowl:细胞核分割2025/01/15·1 分钟项目 Kaggle Segmentation U-Net Medical Imageschool_blog:前后端分离校园博客2024/05/01·1 分钟项目 Campus Blog Frontend/Backend PC Web Mobile Web